


Over the last days, we discussed the second criterium of Trustworthy A.I. called Ethical A.I.. Ethical A.I. is defined by four ethical principles: respect for human autonomy, prevention of harm, fairness and explicability. Today and tomorrow we will dive deeper into the last principle: explicability.
Explicability has a strong connection to the procedural dimension of fairness. The HLEG states this procedural dimension of fairness as the , “ability to contest and seek effective redress against decisions made by AI systems and by the humans operating them.” Thus in order to contest decisions made by A.I. systems, the company responsible for the decision must be “identifiable, and the decision-making processes should be explicable”.
Explicability extends on the procedural dimension of fairness. But before we are going into explicability, let me discuss the difference between explicable and explainable.
Explicable vs explainable
Many people use explainable instead of explicable as they are very similar in usage and mostly used as synonyms. I was wondering why the EU was using explicable instead of explainable and I would now reason that explainable puts the focus rather on the subject and explicable puts the focus rather on the object. I know that sounds a bit confusing.
Let me give you an example: A model which is not explainable just means that the subject or observer is not able to explain the reasoning behind the models decision although it is objectively explainable or has an explanation the person just not know. However a model which is inexplicable does not even have an explanation. For the sake of simplicity, I would like to use explainable from now on as the word is much more known to many people than explicable.
Now that we know the difference between explicable and explainable, let’s see how explainable differs from interpretable. I know this article seems a bit like English class, but when it comes to ethics, words matter.
Interpretable models vs Explainable models
An interpretable model mostly belongs to three families of model classes: decision trees, linear regression of logistic regressions.
A linear regression model for a model could have a simple form as that. Imagine you want to predict the future spending of a client based on their previous purchase. Then the future spendings are Y and the previous spendings are x; b would be a weighing factor.
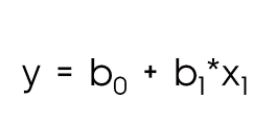
A decision tree model is literally what it sounds like. You make yes/no decisions while you move down a tree of questions:
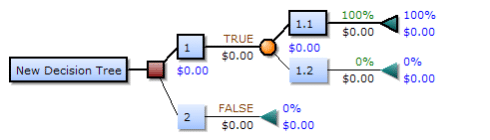
Polyextremophile, Public domain, via Wikimedia Commons
As you see in the above graphic, decision tree models are very well interpretable and it is very easy to check, if these kind of models are biased (e.g. vs ethnicity or any other attribute).
However there are groups of models, which are not interpretable anymore. Few of these groups are called random forest, neural networks or convolutional neural networks. The list of non-interpretable models grows continuously as it is subject of immense research. If a regression model might have 2, 5 or even 20 variables, convolutional neural networks can have millions of variables. Our brain has several billion neurons, while a frog brain has 16 millions. Nowadays we can already simulate frog brains in the computer. But as you see, 16 million neurons/ variables is a black box of interpretability. But this computational power is needed, if you think that a simple image task (bagel vs. puppy) with 100×100 pixels for each image creates a problem with 10,000 dimensions, where each dimension has a multitude of possibilities.
This group of non-interpretable models is called “black-box models”, which can only be tried to be explain and not interpreted anymore.
Many people find that it was not a good choice to choose “interpret vs explain” in this setting as these too verbs seem to be interchangeable. For now we might define the verb explain as “to render understandable” and interpret as “to provide meaning”.
In the following chapter will look into new methods and techniques and how “black box models” can be made explainable.